
Looking back at 2025, smart education has solidified its position as a core industry focus, driving...

Facilitating Scholarly Dialogue on AI, Pedagogy, and Educational Innovation
As ChatGPT, Doubao, Deepseek, and other LLMs (Large Language Models) rapidly enter schools, becoming "new tools" for student homework assistance and teacher lesson preparation, a key issue has gradually emerged. While LLMs can assist teachers in teaching and support student learning, due to the lack of educational theory support and reliance on training data and passive input content, they are prone to generative errors and struggle to accurately match students' personalized learning needs and cognitive development patterns.
How can LLM transition from general information tools to professional partners that understand both education and teaching? The recent three studies provide corresponding answers: The Vanderbilt University team proposed an "Adaptive Scaffolding Framework" that integrates multiple educational theories, enabling LLM teaching agents to achieve dynamic evaluation and feedback. The Shanghai Innovation Institute and other research teams developed the EduAlign framework, which utilizes reinforcement learning to allow AI tutors to embody the three key characteristics of Helpfulness, Personalization, and Creativity. The CoGrader system, developed by a joint team from the Hong Kong University of Science and Technology, reconstructs the project report grading process through human-machine collaboration, striking a balance between efficiency and fairness. The three approaches target the core scenarios of "teaching interaction," "AI tutor reinforcement," and "evaluation processes," providing relevant theoretical frameworks for LLM applications in education.
A Theory of Adaptive Scaffolding for LLM-Based Pedagogical Agents
Vanderbilt University's Institute for Software Integrated Systems, in "A Theory of Adaptive Scaffolding for LLM-Based Pedagogical Agents," presents a framework that integrates ECD (Evidence-Centered Design), SCT (Social Cognitive Theory), and ZPD (Zone of Proximal Development). It proposes a hybrid intelligent assessment scheme that, through the Inquizzitor system, enables formative assessment and feedback, fully leveraging the conversational capabilities of LLMs to update students' understanding states continuously.

Figure 1: Framework for LLM agent adaptive scaffolding
This framework mainly covers, as shown in Figure 1:
(1) The Evaluation Module (blue) mainly includes ECD evaluation, scoring criteria, and the item banking module, which is used to determine the knowledge students have mastered.
(2) The Adaptive Decision Module (Green) primarily uses ZPD and SCT to infer students' learning needs and respond with strategies.

Figure 2: Key components of Inquizzitor
The theoretical framework of this approach specifically and clearly defines the standards and requirements for students' mastery of knowledge, skills, and abilities, and designs activities that can directly yield evidence of their achievement. ZPD connects the evaluation of evidence with adaptive support, predicting the level of students' ZPD through the evaluation process and dynamically adjusting it to ensure the current learning progress exceeds the students' current level. At the same time, SCT determines the specific way of support. The Adaptive Decision Module acquires evidence through the evaluation module, combines the obtained evidence with course knowledge, formative tasks, and grading criteria, and provides real-time feedback to the agent. This framework can provide more personalized feedback based on the actual situation of the students. Students respond to this feedback, and these responses are added to the evidence database, forming a cycle. The agent can then continuously update its understanding of diverse students based on the students' feedback.
The Institute for Software Integrated Systems collected data from 104 sixth-grade Earth science students taught in English during the research period, storing it on a server. Due to reasons such as student absences and system formatting errors, this study generated a total of 3,413 intelligent dialogues and processed 48 million text segments. The authors aim to achieve high-precision evaluation through a hybrid human-machine intelligent approach, integrating it with core learning theories to provide support for educators' autonomy in teaching.
The model has achieved outstanding results in these aspects:
(1) Rating accuracy (RQ1): Consistent with human ratings, and significantly better than human ratings in two of the data sets, fully demonstrating a near-perfect level of consistency. The weighted Kappa statistic indicates that for these two datasets, the index increases as more data is added.
(2) Loyalty (QR2): FKGL ratings averaged 6.7, with feedback content generally aligning with students' current age-related cognitive levels. The system consistently avoids situations where students might attempt to hack or manipulate it, guiding them back on track.
(3) Student perception survey: Students provided overwhelmingly positive feedback, enjoying their interactions with Inquizzitor (average score 3.82) and readily understanding concepts (average score 3.82). In practical use, ratings and explanations showed high perceived accuracy (average score 3.9). However, due to its AI-based nature, respondents generally felt that the rating criteria were rigid, and the AI might exhibit more subjectivity.
During the research process, the authors encountered corresponding limitations when setting goals, finding it challenging to guide students in effectively mastering knowledge. This raised concerns that large models might hinder student learning. Moreover, students care more about grades than feedback provided by large models, a phenomenon that contradicts the original research intent and further exacerbates the difficulties students face in learning. Additionally, due to sample size limitations, it cannot be guaranteed that the findings apply to students of other age groups, in other subjects, or in different language environments. Since a randomized controlled trial was not conducted, the impact of Inquizzitor on learning outcomes and learning behavior remains uncertain.
Cultivating Helpful, Personalized, and Creative AI Tutors: A Framework for Pedagogical Alignment using Reinforcement Learning
LLMs, while bringing more possibilities to digital education, still struggle to align with teaching principles of human-centricity, personalization, and creativity cultivation. While reinforcement learning can simplify reward mechanisms and educational strategies, it often fails to evaluate and meet students' multidimensional needs comprehensively. How can reinforcement learning (RLHF) make large models more like "teachers"—not just providing correct answers, but also being inspiring, creative, and even understanding who you are and what you want to learn. Research teams, such as the Shanghai Innovation Institute, have proposed the EduAlign framework, dedicated to creating more efficient and comprehensive AI tutors through reinforcement learning technology, thereby breaking key bottlenecks in the application of LLMs in the field of education.
The author designed a questionnaire tailored for educational settings, consisting of a total of 8,000 questions, covering three dimensions: practicality, personalization, and innovation.
- Helpfulness-related data: Based on classic moral stories, from the perspective of students, ensuring answers provided meet educational standards
- Creativity-related data: Three teachers are set to generate responses that can cultivate divergent thinking in three typical teaching scenarios
- Personalization-related data: Combining real student profiles, simulating the interactions of three teachers with different performance levels in four types of teaching scenarios
This reward model guides the policy model through these three dimensions, providing a foundation for reinforcement learning. However, to enhance the model's teaching effectiveness in real educational scenarios, the authors also introduce human feedback reinforcement learning, ensuring accuracy while also reflecting the previously mentioned three dimensions of education.
The design of the mechanism primarily adopts the HPC-RM model:
- Helpfulness: The answer should be educationally valuable and contribute to genuine understanding;
- Personalization: Tailor instruction to individual needs, understanding the user's background and requirements;
- Creativity: It's not just about being "correct," but also about inspiring thought and evoking associations.

Figure 3: Prompt template for assessing helpfulness, personalization, and creativity
The training process includes data sampling (selecting inputs from educational prompt datasets), response generation (current model generating multiple candidate responses), reward evaluation (using HPC-RM to score candidate responses and calculate rewards), and policy update (optimizing the model through the policy gradient method while constraining with the KL divergence to prevent the model from deviating from its original capabilities). By adopting a multi-dimensional reward model-guided reinforcement learning approach, the fine-tuned model demonstrates stronger adaptability across three dimensions, significantly outperforming the original model in 100 real educational scenarios. It conveys factual knowledge more effectively and adapts more effectively to students' personalized needs, thereby stimulating their curiosity. The specific test results are as follows:
Edu-Values: Subjective analysis question scores increased from 4.10 to 4.29 (on a 0-5 scale), aligning more closely with core values such as teacher ethics and educational laws and regulations;
PersonaMem: Multiple-choice question accuracy improved, enabling more precise user profiling and generation of tailored responses;
MathTutorBench: The model was evaluated using five key metrics, outperforming the pre-trained model.
The EduAlign framework addresses the current mismatch of LLMs in complex educational scenarios, and more importantly, it provides a reusable solution: using the reward model of HPC-RM, leveraging GRPO technology and an 8000-set dataset, as well as the ability to articulate diverse teaching tasks, laying the foundation for creating warmer and more personalized AI tutors in the future.
CoGrader: Transforming Instructors' Assessment of Project Reports through Collaborative LLM Integration
Project-based learning (PBL) is a core teaching method commonly used to cultivate students' critical thinking and creativity, but the assessment of students during the practical process has long troubled teachers, leading to various issues such as complex assessment indicators, difficulties in standardizing criteria, and the potential for subjective judgment by teachers, resulting in biases. To address these problems, professors from universities such as the Hong Kong University of Science and Technology and Zhejiang University have jointly developed the CoGrader human-computer collaborative assessment system. By integrating LLMs with the professional judgment accumulated through teachers' experience, the system redefines the inherently complex assessment process, simplifying it while maintaining educational fairness and improving efficiency.
The CoGrader system, although based on large language models, still follows a teacher-led, AI-enabled design philosophy. It constructs an entirely new grading system through three core modules, integrating it into the current workflow of teachers. The authors have clarified that this tool is primarily intended to facilitate the collaborative role of humans and AI in the grading of students by teachers. Therefore, during the system design, the authority was placed in the hands of the teachers.
The article clearly explains the function of each component and the steps for using the system, which are briefly introduced as follows:

Figure 4: CoGrader system interface
First is the system's highly intuitive visual interface design, which makes the complex scoring process transparent and visible. The Indicator View (A) provides functions for uploading reports and project requirements (a1) and is equipped with collaborative design tools to generate multidimensional project evaluation indicators (a2). The Benchmark View (B) includes a benchmark comparison area (b1), where users can compare the indicator scores of specified reports with selected benchmarks. The "Selected Indicators" area (b2) below displays an overview of the indicator score distribution for all reports. The Report List area (b3) shows uploaded reports, supporting users in triggering automatic evaluation, viewing and editing AI-generated scores and notes for each indicator, or selecting benchmarks for AI-assisted iterative re-evaluation. The Feedback View (C) presents the content of the specified report (c1), supporting users in reviewing and annotating (c2). Users can also view AI-generated summaries and write final feedback comments for the specified report (c3).
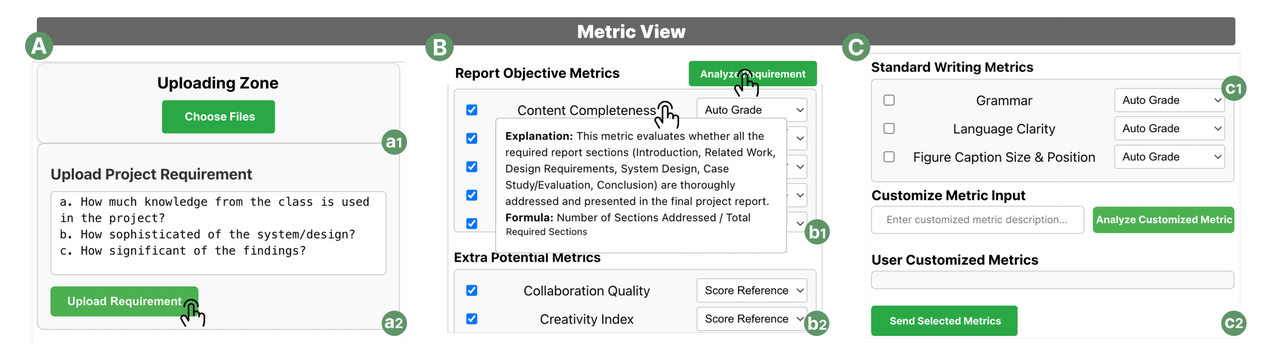
Figure 5: Indicator View Component
Indicator design is the foundation of scoring and also the most time-consuming and effort-intensive in traditional classroom processes for teachers. However, in the CoGrader system, the indicator view combines AI automatic analysis with manual customization to efficiently solve this problem. Teachers first upload two key types of files here: project requirement documents (such as report topics and scoring requirements) and student report files (a1, a2). After clicking the "Analyze Requirements" button, AI will automatically extract two types of indicators (b1, b2): target indicators (indicators that directly match the requirements) and additional potential indicators (indicators that teachers might overlook. If teachers need to evaluate more subjective dimensions, they can customize indicators (c2) through language input.
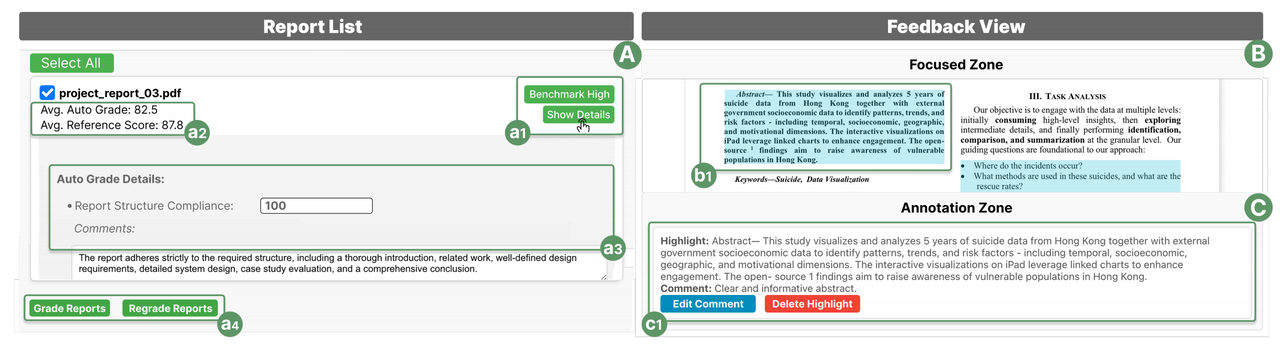
Figure 6: AI preliminary review component
The benchmark is key to resolving fluctuations in scoring criteria. CoGrader achieves a closed loop of AI scoring, teacher-selected benchmarks, and AI re-scoring through the benchmark view component. After uploading the report, the page displays the average score for each indicator (a2), AI comments, and key evidence excerpts (a3).

Figure 7: Benchmark Selection View Component
At the baseline time, teachers can select more representative high and low baseline reports for setting the baseline. Red represents baseline data, and blue represents the current report. Hovering the mouse can display the full name of the indicator and the specific score (a3), making the scoring difference clear at a glance. After setting the baseline, teachers do not need to modify it manually; AI will automatically update the scores and comments based on the baseline. However, teachers can always reject the AI's update results, as the final decision-making power for scoring still lies with the teacher.

Figure 8: Feedback View Component
Teachers can click on a report to access it, enter any report card, and then view the complete report. It supports teachers in annotating key content and adding personalized comments. All annotations and comments are linked to corresponding indicators, becoming a core basis for future reference.

Figure 9: Collaborative View Component
From the collaborative process involving the three major views, AI is responsible for repetitive tasks such as analyzing requirements, initial scoring, and generating suggestions. In contrast, essential steps like metric selection, benchmark determination, and final scoring are determined by the teacher. All AI outputs are accompanied by the original text, allowing teachers to verify the authenticity by referring to the corresponding original content and avoid passively accepting AI conclusions.
The CoGrader system has certain limitations: scores may fluctuate across different attempts, and external code is not included in the evaluation process. However, in actual testing of this system, 12 teachers with project grading experience unanimously agreed that the grading process significantly improved grading consistency and efficiency, greatly enhancing teachers' work efficiency and encouraging active participation and reasonable use of AI. Its innovation lies in breaking the stereotype of AI replacing teachers, achieving optimization for teachers, students, and educational scenarios through a transparent process: reducing teachers' repetitive work, improving grading consistency, and focusing more energy on professional judgment and personalized guidance; students can receive more timely, specific, and comparative feedback; and providing an scalable solution for large-scale assessment of project-based learning (PBL), balancing efficiency and educational equity.
In the future, the team will refine the manual calibration of LLM outputs, advancing collaboration between AI and humans in education while maintaining ethical balance, ultimately aiming to support student progress.
From the Inquizzitor system implementing dynamic teaching tracking through ECD, SCT, and ZPD theories, to the EduAlign framework using the HPC-RM reward model to enable AI tutors to understand personalized teaching better, to CoGrader's teacher-led collaborative grading model safeguarding educational fairness, these three research initiatives collectively demonstrate the value of LLM in the field of education, not only enhancing efficiency but also deeply aligning with academic principles.
Although current research still has certain limitations, it has established a clear framework for the future development of educational AI, grounded in academic theory, allowing technology to serve teaching effectively. In the future, as these frameworks continue to evolve, we can expect to see more temperature-sensitive, methodologically sound, and sufficiently professional LLM teaching tools enter classrooms, injecting more momentum into personalized and high-quality teaching evaluations.
References
-
Cohn, C., Rayala, S., Srivastava, N., Fonteles, J. H., Jain, S., Luo, X., Mereddy, D., Mohammed, N., & Biswas, G. (2025). A theory of adaptive scaffolding for LLM-based pedagogical agents. arXiv Preprint arXiv:2508.01503. https://doi.org/10.48550/arXiv.2508.01503
-
Chen, Z., Wang, J., Li, Y., Li, H., Shi, C., Zhang, R., & Qu, H. (2025). CoGrader: Transforming instructors' assessment of project reports through collaborative LLM integration. arXiv Preprint arXiv:2507.20655. https://doi.org/10.48550/arXiv.2507.20655
-
Song, S., Liu, W., Lu, Y., Zhang, R., Liu, T., Lv, J., Wang, X., Zhou, A., Tan, F., Jiang, B., & Hao, H. (2025). Cultivating helpful, personalized, and creative AI tutors: A framework for pedagogical alignment using reinforcement learning. arXiv Preprint arXiv:2507.20335. https://doi.org/10.48550/arXiv.2507.20335
Author: Yan (Tanya) Tang
Subeditor: Anqi (Angel) Wei
Chief Editor: Yirui (Sandy) Jiang